1. 스키마 조정
# routers 폴더 - schemas.py
from pydantic import BaseModel
from datetime import datetime
from pydantic import Field
from typing import Union
class UserBase(BaseModel):
username: str
password: str
# todo 암호관련 작업 필요하다.
class UserDisplay(BaseModel):
username: str
class Config():
from_attributes = True
class CommentBase(BaseModel):
text: str
username: str
timestamp: datetime
class PopulationQuestion(BaseModel):
age_upper: int | None = None
age_lower: int | None = None
gender: str | None = None
residence_location: list | None = None
class PopulationDisplay(BaseModel):
total_population : int
gender_population: int
total_population_in_range : int
target_percent : float
gender: str
test: Union[str, int, float, list, dict]
class Config():
from_attributes = True
# todo 그래프를 그릴 데이터를 같이 반환할 필요가 있겠다.
class PostBase(PopulationQuestion):
residence_location: str | None = None
height_upper: str | None = None
height_lower: str | None = None
marriage: str | None = None
bmi: str | None = None
personality: str | None = None
education: str | None = None
religion: str | None = None
smoking: str | None = None
drinking: str | None = None
occupation: str | None = None
parent_asset: str | None = None
timestamp: datetime
스키마 전체 코드이다.
class PopulationQuestion(BaseModel):
age_upper: int | None = None
age_lower: int | None = None
gender: str | None = None
residence_location: list | None = None부분 질문의 대답을 처리하기 위해서 클래스를 나누었다.
나이와 키는 상한선과 하한선을 입력 받도록 하였다.
class PostBase(PopulationQuestion):
residence_location: str | None = None
height_upper: str | None = None
height_lower: str | None = None
marriage: str | None = None
bmi: str | None = None
personality: str | None = None
education: str | None = None
religion: str | None = None
smoking: str | None = None
drinking: str | None = None
occupation: str | None = None
parent_asset: str | None = None
timestamp: datetimePopulationDisplay(BaseModel)를 상속받는 클래스로 만들어 보았다.
앞으로 더 진행되면 더 잘게 쪼개서 여러개 상속을 받아서 최종적으로 사용자가 보내기를 눌렀을때 받을 데이터가 모음이 될것이다.
사용자가 입력 부분을 검증할 스키마이다.
대부분 OR 로 빈칸이 되어도 검증 통과를 할수 있도록 하였다.
str로 일단 설정을 해뒀지만 int, list로 변경이 될수 있다.
class PopulationDisplay(BaseModel):
total_population : int
gender_population: int
total_population_in_range : int
target_percent : float
gender: str
test: Union[str, int, float, list, dict]
class Config():
from_attributes = True
# todo 그래프를 그릴 데이터를 같이 반환할 필요가 있겠다.질문을 받고 답변이 나갈때의 스키마이다.
사용자가 나이를 예를 들어 25세~35세로 지정한다면 답변은 예를 들어
전체 인구(total_population)는 5천만이면 남자(gender_population)는 2천5백만 입니다. 25세에서 35세 인구(population_up_to_low)는 오백만이며 20%(target_percent)입니다.
생각을 해보니 단순한 수치 제시에는 4가지 값만 반환하면 되겠지만 그래프를 그릴 계획이 있기 때문에 더 많은 데이터를 반환할 필요가 있겠다. 나중에 수정하도록한다.
이를 토대로 API를 작성해본다.
2. API 작성
#routers 폴더 - population.py
from sqlalchemy.orm.session import Session
from routers.schemas import PopulationQuestion,PopulationDisplay
from fastapi import APIRouter, Depends
from db.database import get_db
from db import db_answer_crud
router = APIRouter(
prefix='/population',
tags=['population']
)
@router.post('', response_model=PopulationDisplay)
def population_questinon(request:PopulationQuestion, db:Session=Depends(get_db)):
if request.age_lower != None and request.age_upper != None:
return db_answer_crud.population_anw(db, request)population.py 파일을 생성하였다.
나이 상한선과 하한선 값이 있다면 db_answer_crud 파일에 population_anw()함수의 결과를 반환하도록 하였다.
if request.age_lower != None and request.age_upper != None:처음에는 조건을 True 로 했는데 테스트에서 0값(0세)를 넣으면 통과를 못하기 때문에 조건을 None으로 변경하였다.
이제 db_answer_crud 파일을 코딩한다.
# main.py
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from routers import user, population
app = FastAPI()
app.include_router(user.router)
app.include_router(population.router)
origins = [
"http://localhost:3000",
"http://localhost:8000",
]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_methods=["*"],
allow_headers=["*"],
)
@app.get('/')
def root():
return "hello world"작성한 API를 main.py 에도 반영했다.
3. DB 관련 변경 사항
# models.py
from db.database import Base
from sqlalchemy import Column, Integer, String, DateTime, ForeignKey
from sqlalchemy.orm import relationship
class DbUser(Base):
__tablename__= 'user'
id = Column(Integer, primary_key=True, index=True)
username = Column(String)
password = Column(String)
items = relationship('DbPost', back_populates='user')
# todo 암호 관련 작업이 필요하다.
class DbPost(Base):
__tablename__ = 'post'
id = Column(Integer, primary_key=True, index=True)
age = Column(String)
height = Column(String)
education = Column(String)
occupation = Column(String)
residence_location = Column(String)
religion = Column(String)
timestamp = Column(DateTime)
user_id = Column(Integer, ForeignKey('user.id'))
user = relationship('DbUser', back_populates='items')
comments = relationship('DbComment', back_populates='post')
class DbComment(Base):
__tablename__ = 'comment'
id = Column(Integer, primary_key=True, index=True)
text = Column(String)
username = Column(String)
timestamp = Column(DateTime)
post_id = Column(Integer, ForeignKey('post.id'))
post = relationship('DbPost', back_populates='comments')
class DbPopulation(Base):
__tablename__ = 'population_statistics'
id = Column(Integer, primary_key=True, index=True)
gender = Column(String)
age = Column(Integer)
total_population = Column(Integer)
seoul = Column(Integer)
busan = Column(Integer)
daegu = Column(Integer)
incheon = Column(Integer)
gwangju = Column(Integer)
daejeon = Column(Integer)
ulsan = Column(Integer)
sejong = Column(Integer)
gyeonggi = Column(Integer)
gangwon = Column(Integer)
chungcheongbuk = Column(Integer)
chungcheongnam = Column(Integer)
jeollabuk = Column(Integer)
jeollanam = Column(Integer)
gyeongsangbuk = Column(Integer)
gyeongsangnam = Column(Integer)
jeju = Column(Integer)
db - models.py 파일에 변경이 있었다.
class DbPopulation(Base):
__tablename__ = 'population_statistics'
id = Column(Integer, primary_key=True, index=True)
gender = Column(String)
age = Column(Integer)
total_population = Column(Integer)
seoul = Column(Integer)
busan = Column(Integer)
daegu = Column(Integer)
incheon = Column(Integer)
gwangju = Column(Integer)
daejeon = Column(Integer)
ulsan = Column(Integer)
sejong = Column(Integer)
gyeonggi = Column(Integer)
gangwon = Column(Integer)
chungcheongbuk = Column(Integer)
chungcheongnam = Column(Integer)
jeollabuk = Column(Integer)
jeollanam = Column(Integer)
gyeongsangbuk = Column(Integer)
gyeongsangnam = Column(Integer)
jeju = Column(Integer)gender 로 남,여로 입력한 부분 이외에는 모두 Interger 가 되었다.
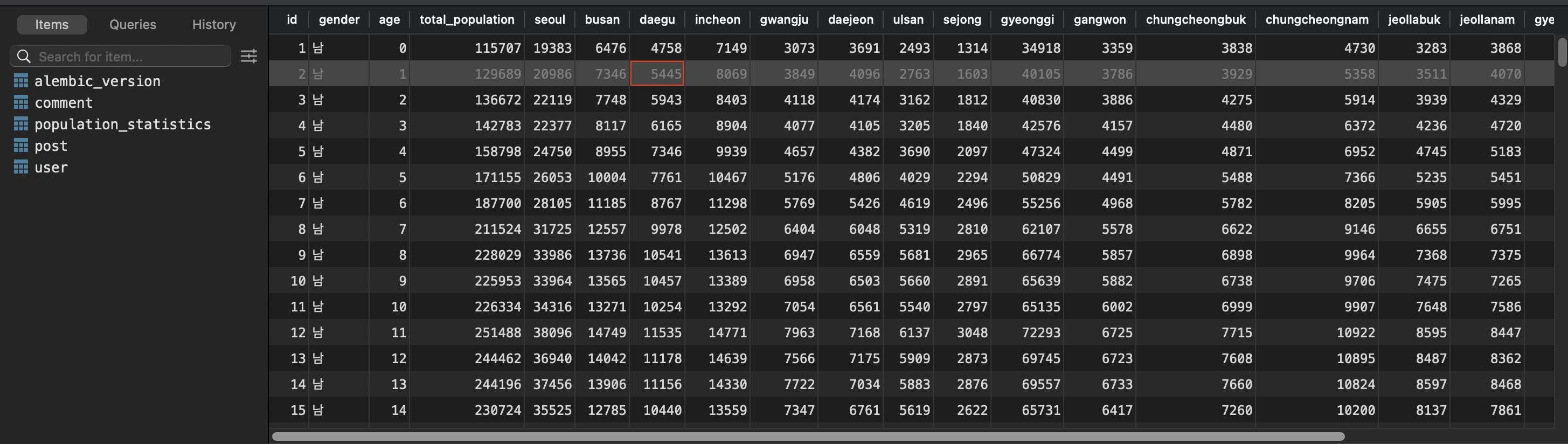
데이터 베이스에 실제 입력값을 다시 넣었다.
age 열은 0세 -> 0, str -> int로 변경되었다.
그리고 총합 관련 행을 모두 삭제하였다.
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from db.models import DbPopulation
from db.database import Base
# your_module은 DbPopulation 클래스를 정의한 파일의 이름입니다.
# 엑셀 파일 읽기 (1행은 건너뛰고 읽음)
excel_file = '/Users/honjun/Downloads/poppulation.xlsx' # 엑셀 파일 경로
df = pd.read_excel(excel_file)
# 데이터베이스에 연결
engine = create_engine('sqlite:///haxagonMan.db') # 데이터베이스 URL에 따라 변경해야 할 수 있습니다.
# 데이터베이스 테이블 생성
Base.metadata.create_all(engine)
# 데이터베이스 세션 생성
Session = sessionmaker(bind=engine)
session = Session()
# 데이터프레임 반복하며 데이터베이스에 행 추가
for index, row in df.iterrows():
if row.iloc[1] in ["남 인구수", "여 인구수" , "연령구간인구수"]:
continue
population_statistics = DbPopulation(
gender=row.iloc[0],
# age= int(''.join(filter(str.isdigit, age_string)) for age_string in row.iloc[1]),
age=int(''.join(filter(str.isdigit, row.iloc[1]))),
total_population=int(row.iloc[2].replace(',', '')),
seoul=int(row.iloc[3].replace(',', '')),
busan=int(row.iloc[4].replace(',', '')),
daegu=int(row.iloc[5].replace(',', '')),
incheon=int(row.iloc[6].replace(',', '')),
gwangju=int(row.iloc[7].replace(',', '')),
daejeon=int(row.iloc[8].replace(',', '')),
ulsan=int(row.iloc[9].replace(',', '')),
sejong=int(row.iloc[10].replace(',', '')),
gyeonggi=int(row.iloc[11].replace(',', '')),
gangwon=int(row.iloc[12].replace(',', '')),
chungcheongbuk=int(row.iloc[13].replace(',', '')),
chungcheongnam=int(row.iloc[14].replace(',', '')),
jeollabuk=int(row.iloc[15].replace(',', '')),
jeollanam=int(row.iloc[16].replace(',', '')),
gyeongsangbuk=int(row.iloc[17].replace(',', '')),
gyeongsangnam=int(row.iloc[18].replace(',', '')),
jeju=int(row.iloc[19].replace(',', '')),
)
session.add(population_statistics)
# 변경사항 커밋
session.commit()
# 세션 종료
session.close()
데이터를 넣을 때 사용한 코드이다. 몇번 안할 작업이라 수작업이라고 해도 상관은 없지만 효율적인 작업을 위해 고민을 해봐야 할 부분이다.
4. DB 작성
from sqlalchemy.orm.session import Session
from sqlalchemy import func, and_, or_
from db.models import DbPopulation
from routers.schemas import PopulationQuestion, PopulationDisplay
def population_anw(db: Session, request: PopulationQuestion):
# 남성과 여성 데이터를 한 번에 쿼리하여 필터링
filtered_population = db.query(DbPopulation)
# 총 인구수 계산
total_population = filtered_population.with_entities(func.sum(DbPopulation.total_population)).scalar()
if request.gender:
filtered_population = filtered_population.filter(DbPopulation.gender == request.gender)
# 성별 인구수 계산
gender_population = filtered_population.with_entities(func.sum(DbPopulation.total_population)).scalar()
# 타겟 연령별 인구 계산
if request.age_lower != None and request.age_upper != None:
filtered_population = filtered_population.filter(and_(DbPopulation.age >= request.age_lower,
DbPopulation.age <= request.age_upper))
# 특정 지역 인구
total_population_in_range = 0
if request.residence_location:
# location_list에 포함된 열 index만 남기기
location_list = [location for location in request.residence_location]
# location_list에 있는 열만 필터링
filters = [getattr(DbPopulation, location_column) for location_column in location_list]
filtered_population = filtered_population.filter(or_(*filters))
# 필터링된 열의 값들의 총합 계산
for population in filtered_population:
for location in location_list:
total_population_in_range += getattr(population, location)
# 지역 입력값이 없으면 타겟 연령별 인구의 총합으로 한다.
else:
total_population_in_range = filtered_population.with_entities(func.sum(DbPopulation.total_population)).scalar()
# 타겟 퍼센트 계산
if gender_population:
target_percent = round(total_population_in_range / gender_population * 100, 2)
else:
target_percent = 0.0
population_res = PopulationDisplay(
total_population=total_population,
gender_population=gender_population,
total_population_in_range=total_population_in_range,
target_percent=target_percent,
gender=request.gender,
test=1
)
return population_res나름 작성을 하여 제대로된 경과를 뽑아 내는데 성공했다.
챗gpt에게 코드를 효율적으로 바꿔달라고 요청했더니 상당히(!) 다른 코드를 주었다.
하지만 이상하게 작동하지 않아서 약간 손을 볼 필요가 있었다.
# 남성과 여성 데이터를 한 번에 쿼리하여 필터링
filtered_population = db.query(DbPopulation)
# 총 인구수 계산
total_population = filtered_population.with_entities(func.sum(DbPopulation.total_population)).scalar()데이터 베이스에서 그대로 가져온다. 현재 남,녀 인구 순수한 데이터만 남아 있기 때문에 그대로 가져왔다.
필터링한 인구에서 total_population 열을 모두 합해서 총인구 계산을 했다.
if request.gender:
filtered_population = filtered_population.filter(DbPopulation.gender == request.gender)
# 성별 인구수 계산
gender_population = filtered_population.with_entities(func.sum(DbPopulation.total_population)).scalar()입력한 성 값이 있으면. 남자면 남자로 필터링하여 다시 저장했다.
똑같이 필터링한 데이터의 총합으로 남자 인구의 총합을 구한다.
# 타겟 연령별 인구 계산
if request.age_lower != None and request.age_upper != None:
filtered_population = filtered_population.filter(and_(DbPopulation.age >= request.age_lower,
DbPopulation.age <= request.age_upper))입력한 연령 구간이 있다면 그 구간만 남기도록 필터링을 걸었다.
# 특정 지역 인구
total_population_in_range = 0
if request.residence_location:
# location_list에 포함된 열 index만 남기기
location_list = [location for location in request.residence_location]
# location_list에 있는 열만 필터링
filters = [getattr(DbPopulation, location_column) for location_column in location_list]
filtered_population = filtered_population.filter(or_(*filters))
# 필터링된 열의 값들의 총합 계산
for population in filtered_population:
for location in location_list:
total_population_in_range += getattr(population, location)
# 지역 입력값이 없으면 타겟 연령별 인구의 총합으로 한다.
else:
total_population_in_range = filtered_population.with_entities(func.sum(DbPopulation.total_population)).scalar()특정 지역이라는 입력값이 있으면 특정지역의 인구만 필터링한 후 총합을 구한다.
지역 입력값이 없으면 위에서 연령으로 필터링한 값의 총합을 구한다.
# 타겟 퍼센트 계산
if gender_population:
target_percent = round(total_population_in_range / gender_population * 100, 2)
else:
target_percent = 0.0
population_res = PopulationDisplay(
total_population=total_population,
gender_population=gender_population,
total_population_in_range=total_population_in_range,
target_percent=target_percent,
gender=request.gender,
test=1
)
return population_res
마지막으로 구간 인구/성별 총인구를 나눠서 소수점 둘째자리까지 표현하였다.
결과는 API에서 반환 모델을 PopulationDisplay를 모델로 하기 때문에 그 형식에 맞춰서 작성한 것이다.
(test=1은 삭제)
5. 테스트 결과
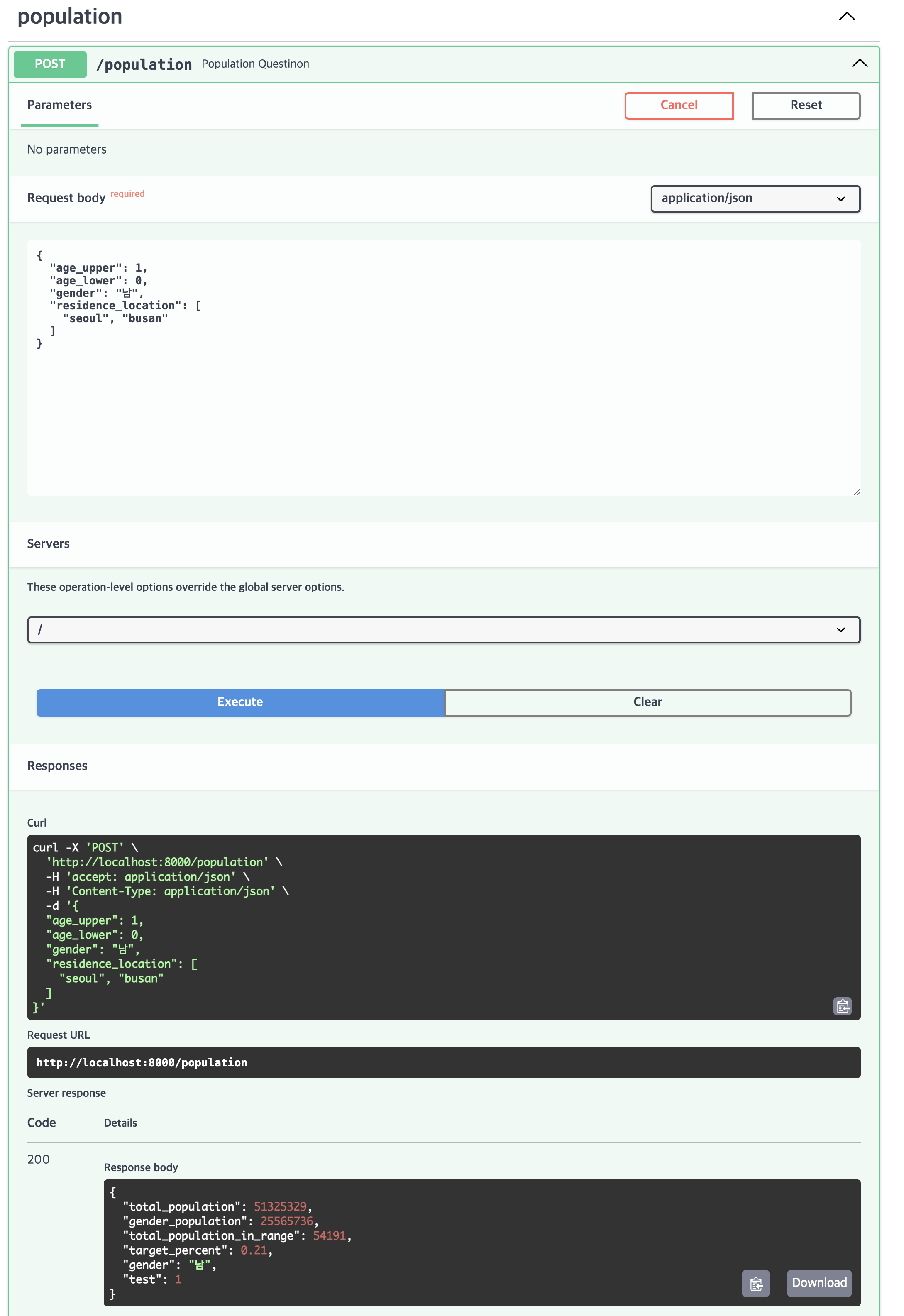
스웨거 UI를 통해서 확인한 모습
총인구, 남자 총인구, 0~1세 총인구, 남자 총인구 대비 0~1세의 비율, 입력한 성별이 순서대로 출력되는 것을 확인할수 있었다.
나이 하한선을 0세로 입력해도 통과가 된다. 하지만 버그 방지를 위해서 API파라매터 입력의 값을 1세에서 100세로 제한해둘 필요가 있겠다.
서울과 부산 복수의 값을 리스트로 입력해도 잘 작동하는 것을 확인했다.
이제 테스트 해볼 백엔드의 형태를 갖췄으니 프론트 엔드 작업을 해봐야 겠다.
'파이썬 > 육각남 찾기 프로젝트(FastAPI+React)' 카테고리의 다른 글
| 육각남 찾기 프로젝트 15. 다시 백엔드 구체화하기 (0) | 2024.03.19 |
|---|---|
| 육각남 찾기 프로젝트 14. 나머지 입력 박스 추가하기 (0) | 2024.03.18 |
| 육각남 찾기 프로젝트 12. 챗 GPT로 프론트앤드 UI 꾸미기 (0) | 2024.03.17 |
| 육각남 찾기 프로젝트 11. React 헬로 월드 (0) | 2024.03.16 |
| 육각남 찾기 프로젝트 9. 통계 자료 조작과 데이터 베이스에 넣기 (0) | 2024.03.14 |
| 육각남 찾기 프로젝트 8. 통계자료 찾기 (0) | 2024.03.13 |
| 육각남 찾기 프로젝트 7. 로그인 암호 암호화하여 저장하기 (0) | 2024.03.13 |
| 육각남 찾기 프로젝트 6. 스키마 작성과 유저생성 기능 구현 (0) | 2024.03.11 |